

Архив недели
Понедельник
Привет! На этой неделе с вами Алиса Хорошавина. AI Researcher (NLP, CV). Названия компаний не раскрываю, чтобы не сдерживаться, когда хочется шутить и зачищать кожаных.
Я еще ничего не написала, кроме намерения зачищать кожаных мешков, а уже +100 зрителей моего недельного стендапа!
Весь день не могла написать сюда, потому что мы с админом жестко и громко настраивали инфраструктуру😏
Можно подумать, я сплю с админом, чтобы он настраивал за меня инфраструктуру и давал погонять свои мощные железки для расчетов. На самом деле, это он спит со мной, чтобы мои сетки распознавали лица кожаных мешков, которые он хочет зачистить. Все же знают, какие админы мизантропы?
Вторник
@itunderhood Bdsm в какой день будет?
В принципе вся неделя моего стендапа – это бдсм для тех, кто любит важно надувать щеки😊 twitter.com/vit_wishez/sta…
Темы недели:
1 - кул стори
2 - как удалить ню из твиттера, чтобы они не индексировались поисковыми системами
3 - мозги большого брата: анализ новостей
4 - распознавание лиц на конференциях
5 - диалоговые системы
6 - как собеседовать компанию
7 - программы для electric play
Ранее я стендапила в коллективном твиттере для дата саентистов, рассказывала в основном про анализ текстов, которым занимаюсь 4 года ds.underhood.club/XOR0SHA2wine
Пока админ делал мне Jupyter Notebook на внешнем сервере с SSL, он попивал вино (последняя бутылочка Briego в Москве) и рассказывал кул стори.

Например, он как-то презентовал проект перед заказчиками. Рассказывал про динамическую маршрутизацию OSPF в VPN туннелях (по два на объект). А технический директор спросил про цвета пачкордов в кроссироке коммутационной стойки.
- А провода у вас красные?
И пришлось отвечать, сохраняя серьезный невозмутимый вид. Договор подписали. Никто из присутствующих манагеров не понимал сути вопроса. Но у заказчика был вид профессора, который говорит:
- ну ладно, давай зачетку
Одна контора раз в две недели просила срочно разобраться с тем, что вышел из строя ИБП APC Smart-UPS SRT 10000 ват. С такой четкой регулярностью, что уже шутили – надо планово по графику высылать отряд спасателей APC. Через 3 мес. мой админ уже сам поехал на объект разбираться.
Остался на ночь на объекте и ждет... Появляется жуткий рев из темноты. Он идет к APS и вдруг видит картину: охранник воткнул чайник mulinex в серверную стойку. И с невозмутимым видом заваривает чай. Оказалось, охранник делал это по ночам в свою смену, в среду раз в две недели...
Утром охранник уходил и не видел последствий того, что он палил инвертора. Выбирал именно эту розетку, потому что других не было. Все остальные дежурили без чая, а этот оказался сообразительным. Нашел одну из немногих вещей, сопротивление которых способно вывести из строя ИБП!
Сегодня мы поспорили с админом про нейросети. Он набросил, что это не более чем маркетинг! Я рассказала про случаи, когда приближение функции по данным удобнее, чем высчитывание коэффициентов. Про скрытые зависимости в данных, которые можно выявить за счет анализа большого объема

Он расстроился и перепил медового ликера. Оставшийся день я разгребала последствия, поэтому опять сегодня стендапю поздно😄 Поговорим о Большом брате, потому что сегодня 23 февраля! Военные уже несколько лет финансируют разработки по мониторингу новостей: оппозиция и геополитика.
Есть компании, которые парсят новости со всего рунета. Я тоже умею парсить и даже писала многопоточный парсер на Go. Но это не годится для промышленных объёмов парсинга. Можете подглядеть в замочную скважину на пайплайн Scrapinghub, например: github.com/scrapinghub
Я занималась анализом новостей методами ML на двух местах работы с разрывом в 3 года. Но чувство, что заказчик не менялся. Данные и задачи одни и те же. Есть некое энтерпрайзное приложение под Astra Linux с ML модулями. Эти модули заменяют, когда появляется более точное решение.
Среда
Какие модули есть в системе мониторинга новостей всего рунета.
Выделение трендов в новостях. На этапе экспериментов сначала делается кластеризация, чтобы понять, какие примерно темы есть в потоке с 15 тыс. СМИ. Затем размечаются данные и пишется рубрикатор для продакшена...
Для кластеризации я обычно применяла тематическое моделирование с помощью BigARTM или LDA из gensim. Первый вариант интересен с исследовательской т.з., когда хочется поиграться с модальностями. Например, добавить мод. время и отслеживать появление и затухание новостей во времени.
Четверг
Но в BigARTM приходится эмпирически настраивать гиперпараметры, наблюдая за графиком перплексии. Даже автор ARTM Воронцов признает: «Поиск оптимальных траекторий регуляризации в пространстве коэффициентов регуляризации пока остаётся открытой проблемой». — dialog-21.ru/digests/dialog…
Такое математически изящное решение, а параметры подбираются на глаз! А по значению перплексии можно сравнивать только модель, обученную на одних и тех же данных, но с разными гиперпараметрами. «Единственный человек, с которым вы должны сравнивать себя, это вы в прошлом»©️BigARTM
В этой таблице перплексия ни о чем не говорит, но можно сравнить скорость разных инструментов для Topic Modeling. LDA из sklearn и из Vowpall Wabbit - однопоточные и неэффективные. LdaMulticore из gensim многопоточная, но медленнее BigARTM, т.к. в BigARTM ядро реализовано на С++.

Пятница
В общем, LDA подходит для выделения достаточно крупных тем, вроде «внутренняя политика», «геополитика». BigARTM – для выделения специфических тем, например этнические, религиозные конфликты, митинги. За счет регуляризаторов (разреживание, сглаживание тем по словам)
Суббота
Доброе утро!☕️ Под свежесваренный кофе и Radiohead сейчас наверстаю то, что не успела дорассказать по плану в прошлые дни.

@itunderhood Очень интересно, но нихера не понятно!
Для продакшена, а не исследований – хватит понимания, какой инструмент выбрать. Если темы весьма специфичны, то будет больно. Придется мучаться с коэффициентами регуляризации ARTM и смотреть на топы слов, оценивая интерпретируемость тем и насколько они отличаются друг от друга... twitter.com/ekleziasst/sta…
И добиваться уменьшения перплексии. Можно отслеживать это по ее графику. По оси Х - кол-во итераций, по оси Y - значение перплексии. Нужно, чтобы перплексия была как можно меньше. При этом итераций тоже было как можно меньше, иначе модель переобучится
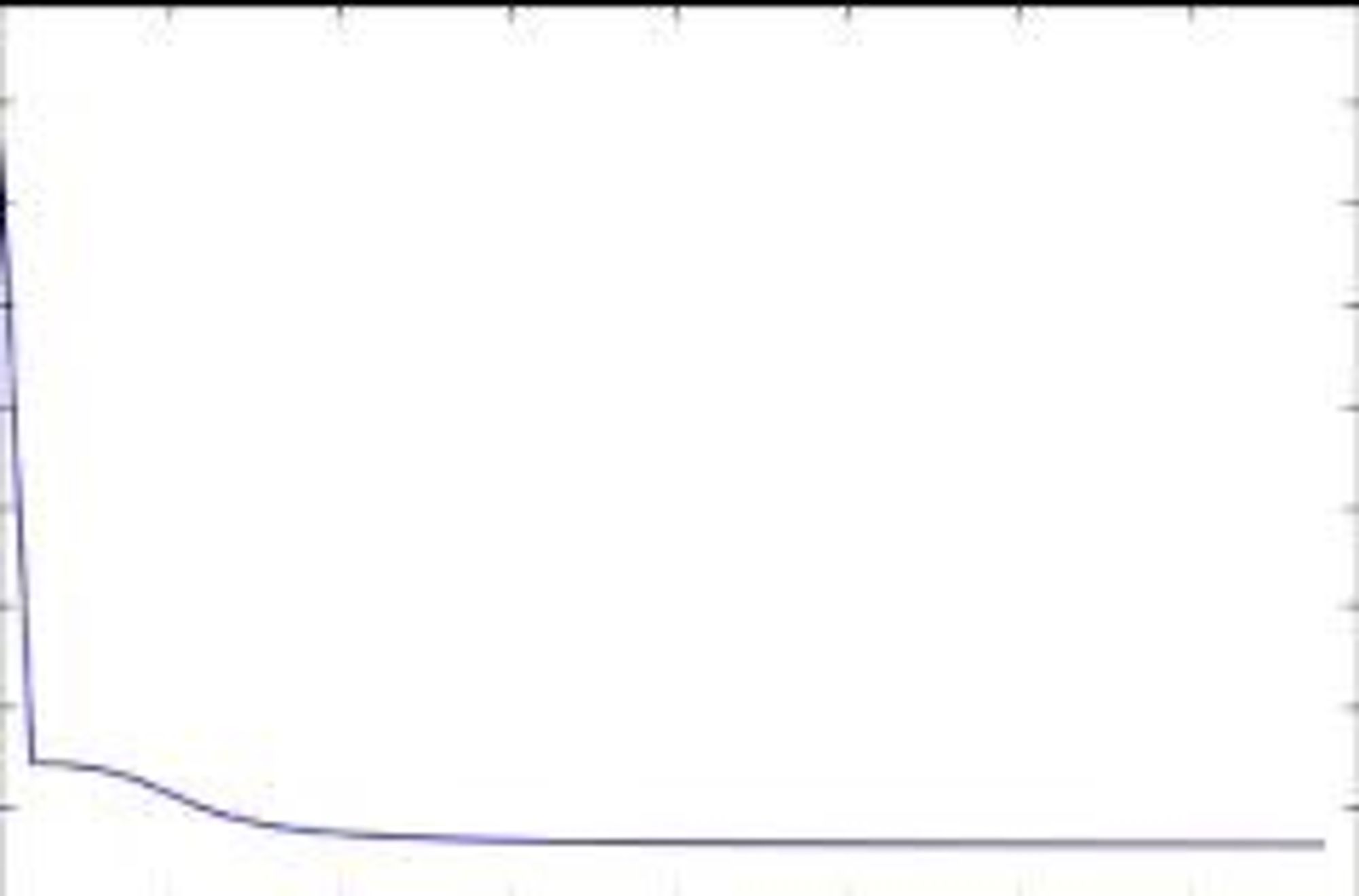
А если темы достаточно крупные и хорошо различимы, то хватит LDA, там меньше параметров. Нет коэффициентов регуляризации. Смотреть придется только на топы слов для каждой темы.
P.S. Здесь остались только те, кто любит математику! Остальные забанены.

Какие еще есть модули есть в системе мониторинга новостей всего рунета.
2) Анализ репутационных рисков.
NER + сентимент. С помощью NER ищут определенные ФЛ и ЮЛ и анализируют тональность контекста упоминания. SOTA для NER сейчас - Deeppavlov, Natasha, для сеентимента - Dostoevsky
@itunderhood Для визуализации что-то используете? Какие-то инструменты типа такого?: https://t.co/amB36oZycQ
Можно использовать распределения тем в тексте как эмбеддинги текстов. И применять к ним алгоритмы кластеризации, визуализации. Например, k-means + TSNE twitter.com/serg_rubtsov/s…
Хороших решений по анализу сентимента на русском нет, тем более - относительно именованной сущности. Поэтому анализируют текст целиком, где встречается ФЛ/ЮЛ. Иногда используют синтаксический разбор (syntaxnet) и соединяют частицу "не" через _ со словом, к которому она относится.
То есть явный негатив и оскорбления в сторону ФЛ/ЮЛ можно найти автоматически. А иронию и сарказм - нет. Такое находят вручную. Спалиться можно скорее не из-за такого текста, а из-за подписок на определенные группы и друзей. Строится граф связей, анализируются темы пабликов.
Вторник
О, я еще с вами? Тогда вот вам тех порно

@itunderhood а выбросы как-то регулировались? в плане какие-то редкие слова в текстах и т.д
1/3
Есть несколько способов борьбы с этой проблемой в текстах.
Тематическое моделирование само по себе убирает наиболее редкие и наиболее частотные слова
Можно усилить это, если отсеять слова с самым большим IDF (очень редкие) и с самым маленьким (общеупотребительные слова) twitter.com/logerk46/statu…
2/3
3) Неюникодные символы, числа, пунктуацию убрать regex
4) Также убрать местоимения, предлоги, междометия и общеупотребительные слова. В nltk есть список stopwords. Его можно дополнять «мусором» из топ слов тем. Для каждого датасета – свои слова, не несущие смысловой нагрузки.
3/3
5) Лемматизация (приведение в начальную форму) или стемминг (оставляем только основу слова)
6) Убираем все тексты меньше N слов (N определяем, глядя на гистограмму длины текстов в словах)
Среда
Как удалить все нюдсы в твиттере? Вручную не получится, потому что старые твиты не подгружаются. Не получится детектировать ню предобученной опенсорсной моделью и удалять их через api твиттера, т.к. api отдает максимум 3200 твитов. Есть вариант получать ссылки старых твитов...
Кстати, если захотите побаловаться с моделями детектирования ню, то поиск по гитхабу по слову nsfw много вариантов возвращает. Вот, например: github.com/GantMan/nsfw_m…
Challenge: попробуйте детектировать как ню вот это скромное фото. Найдете такую рентгеновскую модель?

@itunderhood Вот вариант: скачать архив всех своих данных и там уже парсить твиты help.twitter.com/en/managing-yo…
Этот вариант отдает статический контент, а нам для этой задачки нужны ссылки для удаления twitter.com/litleleprikon/…
@itunderhood Разве через поиск с "since:" и "until:" нельзя ограничения обойти? Ну и "from:" для фильтра по автору
Ручной поиск вынудит удалять тоже вручную, а вы представьте себе аккаунт с 10000 твитов, где нюдсы в каждом втором? twitter.com/kestl/status/1…
@itunderhood Так зачем их удалять, если старые твиты не подгружаются... 🤔
По ключевым словам можно найти. Чужими лайками в ленту выносит. Поисковые системы индексируют. twitter.com/sibiryoff/stat…
Четверг
@itunderhood Если по 10 секунд на твит, то выйдет 14 часов. Т.е. проще заплатить 2-3тр какому-нибудь студенту. А про автоматизирование - один хер в итоге придется перепроверять результат вручную, врядли твоя модель на 100% корректно детектит то, что тебе нужно.
Мне нравится этот еврейский подход! Но я не ищу лёгких путей и выбрала вариант для любителей головоломок twitter.com/dno_krizisa/st…
@itunderhood В целом проблемы нет. Вытащить всю медиа можно через внутренний поиск или внешние поисковые системы и получить прямой линк на них. Однако, нельзя точно распознать ню или нет из-за возможных ошибок сетки. Проверять повторно самому или толокерами
Да, через внешние поисковые системы. Но без нейронки для детектирования ню. Если производить запросы в детском режиме хромиума, мы задействуем их встроенную нейронку для фильтрации контента 18+. twitter.com/0rdinatus/stat…
Сначала получаем список всех ссылок на твиты. Затем пытаемся загрузить каждый в детском режиме. Где отдает ошибку - там нюдс. Сохраняем эту ссылку в «проскрипционный» список😄 Затем зачищаем твиты из проскрипционного списка.
Потребуются:
• Отладчик GET, PUT запросов (в запросах передается твиттерский ник)
• wget + хеши логина пароля + кукис - по ссылкам которые уже есть удаляем (надо будет доконструировать ссылки для зачистки, например добавить ‘/y’ чтобы автоматически подтверждать удаление)...
@atnimak_ @itunderhood А если наоборот - модель пропустит что-то? Хочу отметить, что за студентом так же придется перепроверять, если по-хорошему. Но студент хотя бы приятное с полезным совместит. Еще, кстати, в отдельно взятом аккаунте можно детектить ню по кол-ву лайков относительно среднего
Предлагаю использование модели, встроенной в браузер хрома, которая используется для детского режима twitter.com/dno_krizisa/st…
@dno_krizisa @itunderhood А зачем руками проверять? Если мы удалим несколько лишних твитов, ну и хуй с ним. Страшнее, если мы пропустим несколько твитов к удалению, тут приходиться надеяться, что разработчики хромиума рассуждают так как мы "лучше не показать детям безопасную картинку, чем показать сиськи"
Согласна, в этой задаче полнота важнее точности. Поэтому мы будем оценивать качество по метрике F1 с коэффициентом который позволяет сделать более значимой полноту twitter.com/atnimak_/statu…
• Как предоставляется robots.txt (если аккаунт закрытый, понадобится хеш API Key для индексации закрытого аккаунта)
• файл robots.txt можно создать локально и отправлять рекурсивные запросы через nginx, прикидываясь поисковой системой, чтобы добраться до старых твитов
• Описание протоколов поисковых систем
• Доступ к немецким серверам Amazon (например, оттуда получается прикинуться роботом поисковой системы)
Когда этот проект будет закончен, я напишу больше технических деталей в своем личном аккаунте @XOR0SHA2wine



